 |
settle down and have another cup of coffee
|
TLDR
There are a lot of Russian’s talking to a lot of Trump campaign members in Mueller report. There are so many it’s tough to get your head around it all. In this post I attempted some network analysis on the relations between campaign officials and Russians. I found that one can ‘compress’ Russian involvement into 9 (mostly) distinct groups. I then summarize these points of contacts.
Introduction to Mueller Report
Volume 1 of Mueller Report starts with Russian interference in 2016 US Presidential Elections. Russia did so in two Ways.
The first was a campaign by the IRA that used social media tools like facebook and twitter with the goal of changing public opinion. While there were some retweets by Trump and his campaign officials from these accounts there wasn’t much direct communication.
The second form was to use Russian intelligence to hack Hillary Clinton's emails. These hacked emails were released with help of wikileaks and guccifer 2.0. Trump’s campaign deliberately tried to find other hacked emails and encourages Russia to do so public. However, the campaign could not find additional information on these emails.
The rest of Volume 1 discusses the numerous relationship between trump campaign officials and Russians. It’s this part that will be the basis for most of the results below.
The data
Volume 1 consists of 199 pages including foot-notes and appendices. I found a machine readable version
here. I split the text into sentences and looked at whether a person’s name was included in that sentence. This left me with a sentence by name matrix that is the starting point of my analysis. There are some drawbacks to this in that OCR does not immediately distinguish sentences. In addition it often groups footnotes with last line of sentences in a page. But it seemed like a good starting point so went ahead.
Below are the top 20 most common occurring names.
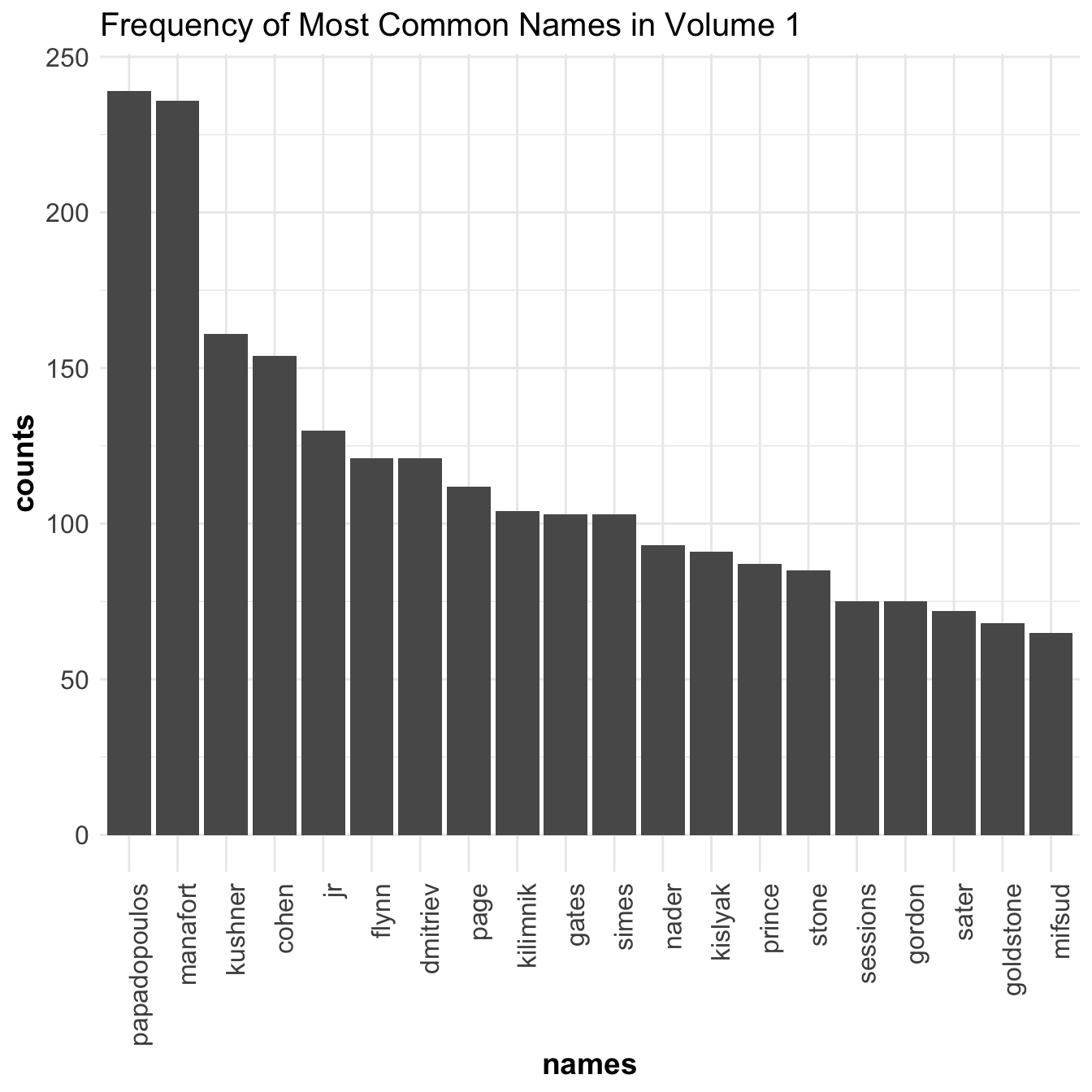
Papadopulos, Manafort, Kushner, Cohen, Trump JR, and Flynn are all in the top. Considering they were all, to varying degrees, worked in the Trump campaign this makes sense. We also see some Russian names such as Dmitriev, Kilimnik, and Kislyak. I’ll explain their contacts below.
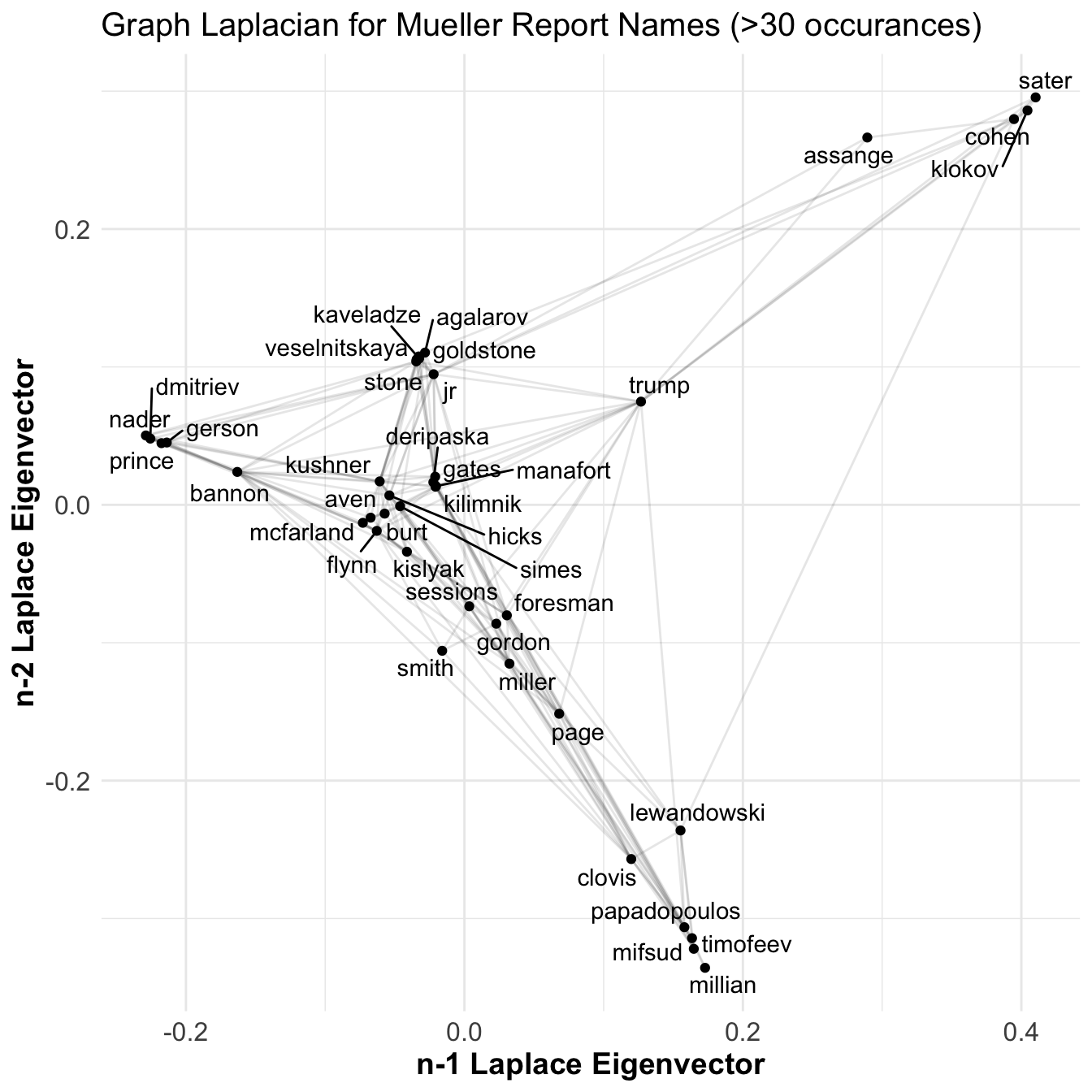
I then created a person x person matrix that counted the number of times a name co-occurs with another. I’m treating this as a weighted, undirected graph. I transformed this to a laplacian matrix and performed an eigen decomposition. This is known as a spectral analysis of a network. Basically this tries to find locations that minimizes the square error of the relations. Below is the resulting image of 2nd to last and 3rd to last eigenvectors.
WHOA … I’m getting a headache looking at this.
But it definitely looks like there is structure in the graph. There appears to be some clusters forming and these do correspond to particular events described in the report. In the lower left you can see Papadopoulos related characters, in the upper right some cohen acquaintances, and around 0,.1 there’s the trump tower meeting. Not bad but still messy. I’m looking for distinct clusters.
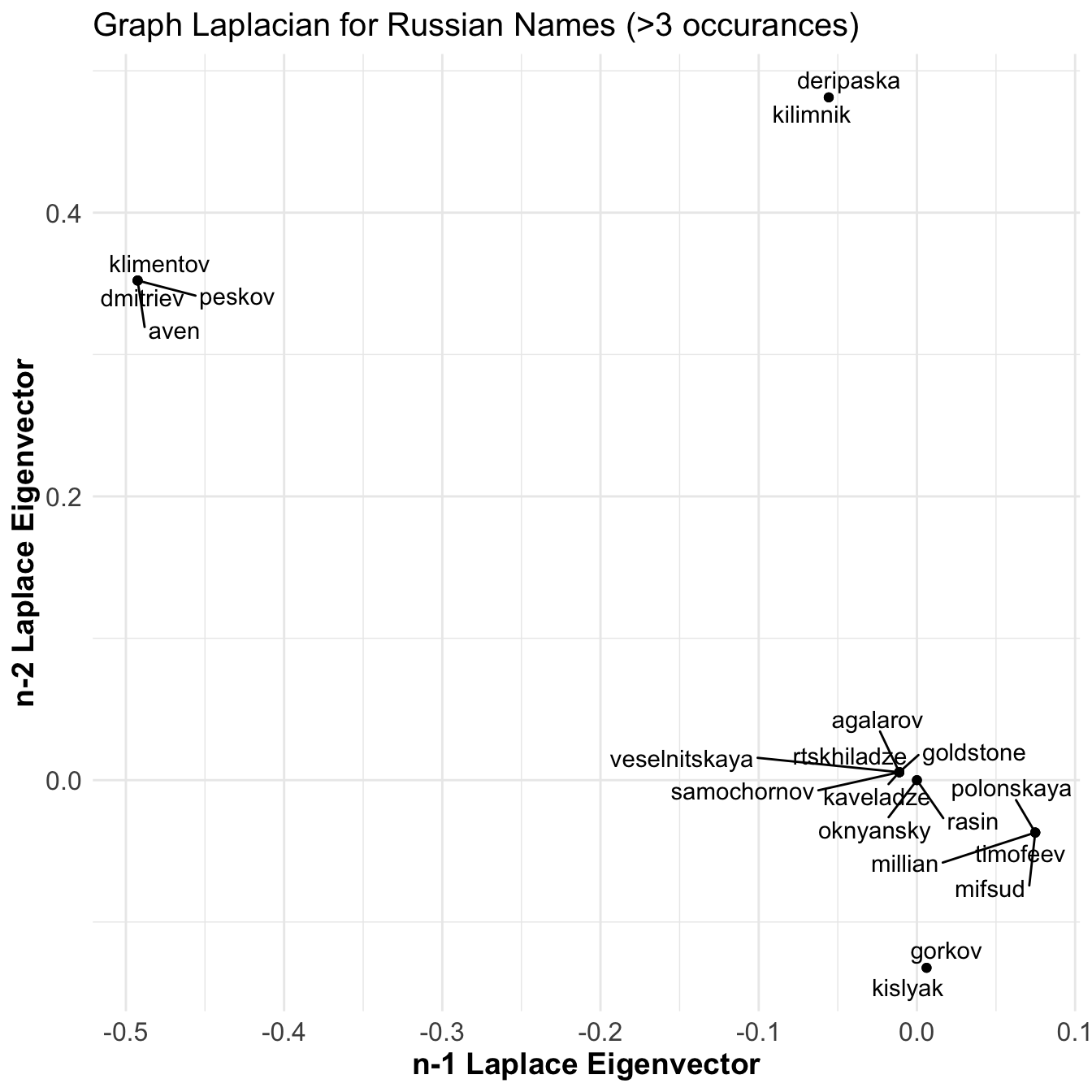
What if we look at only the Russians in the graph?
Ok! Now we’re talking. There are 6 distinct clusters of Russians here. That means there are no relations between these clusters and each correspond to a unique set of relations with trump campaign officials. I played around with this some more but the text data was too messy to have robust analysis. Co-occurring names do not pick up everything and due to sentence parsing errors somethings lead to erroneous relations.
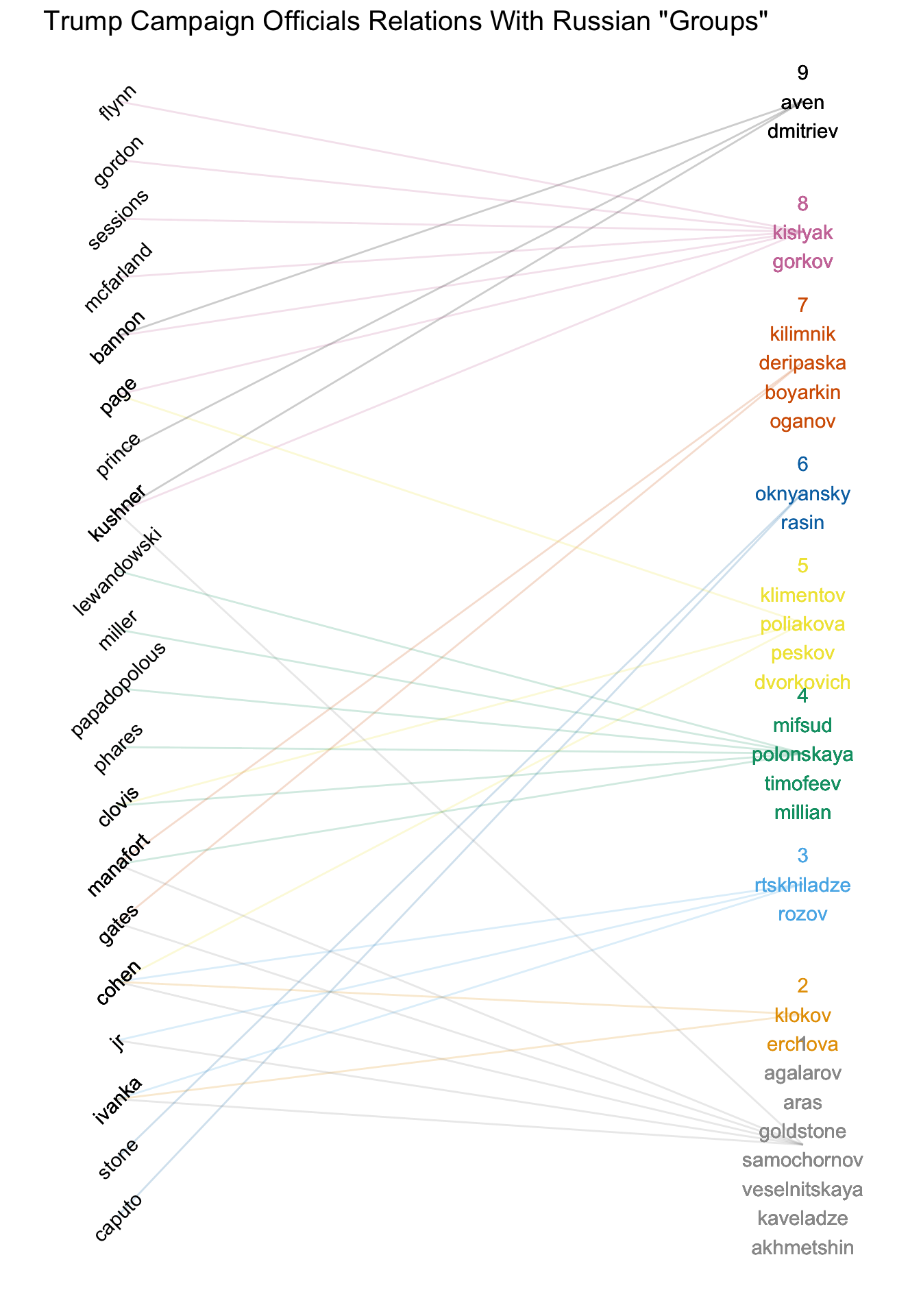
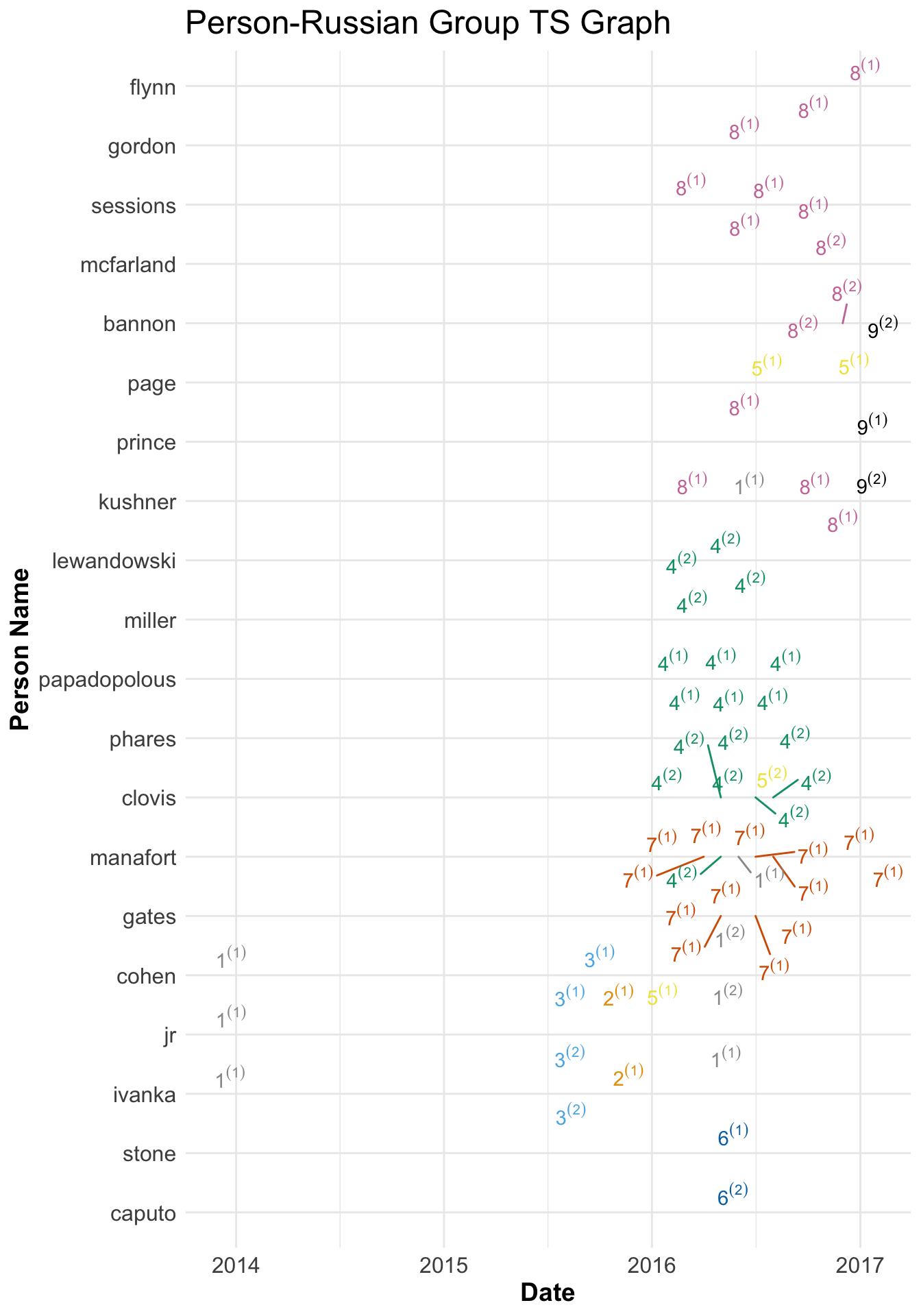
Finally, I gave up on trying to only use text analysis, read volume one, and manually created a network found here. With that I created groupings using the above chart as a starting point. I found 9 fairly distinct clusters of Russians. Below you can see the relationships between those groups and various members of the Trump campaign.
I then further grouped them into 4 broad categories which I’ve named; Trump Business, The Opportunists, The Professionals, and Russian Officials and Lackeys. I also included whether a trump campaign officials interaction was of first degree (they were in meeting or talked explicitly with Russian Group in question) or second degree (they were aware of meeting). Below are my summaries for each.
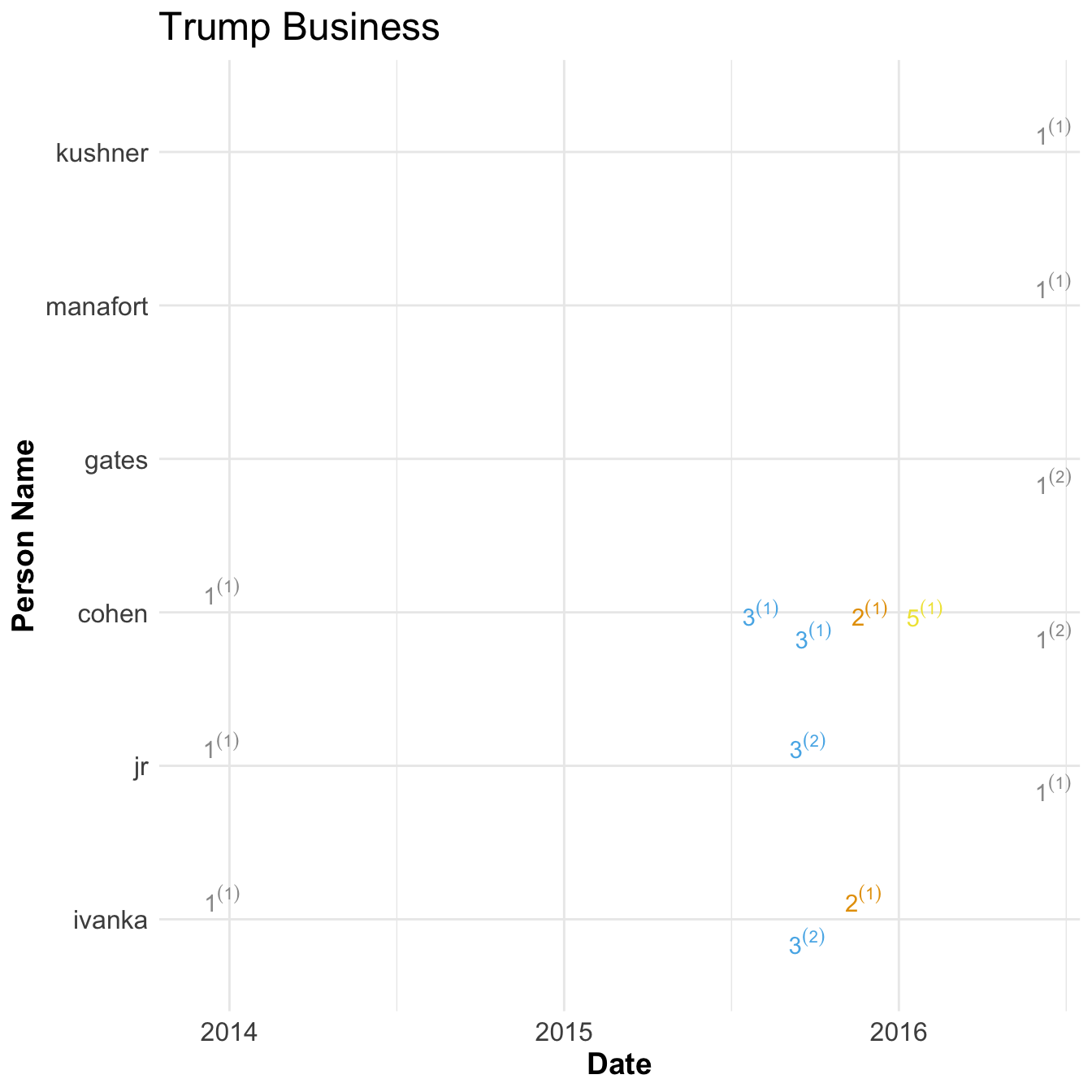
Trump Business
- Group 1
- agalarov, aras, goldstone, samochornov, veselnitskaya, kaveladze, akhmetshin
- Group 2
- Group 3
- Group 5
Aras Agalorov (he has a son Emin. I did not disambiguate the difference between them) is a billionaire Russian Property Developer that worked with trump to create Miss Universe Pageant in 2013. They Discussed creating a Trump tower in moscow in late 2013 and discussed with Donald Trump JR (DTJ) and Ivanka Trump but did not progress.
In Summer of 2015 Group 3 signed a letter of intent to build the trump tower in moscow and met with Ivanka and DTJ.
While this was happening Group 2 contacted cohen to discuss Trump tower in moscow and a meeting with Trump. Cohen thought this person was a pro-wrestler but that did not seem to bother and agreed to talk about business. They wanted to set up a meeting with Trump and Putin but Cohen wanted to keep clear of politics and it went nowhere.
Finally, due to the slowness of progress in Trump Tower Moscow deal from Group 2 cohen reached out to Peskov, Press Secretary for Putin, to try and get in touch with Putin directly and begin building. Cohen worked on moscow deal through summer of 2016 but it went nowhere.
During campaign the Emin Agalorov, at the behest of his father, setup a meeting with DJT to discuss hacked emails. This lead to the infamous Trump Tower meeting that involved DJT, Kushner, and Manafort and other Russians in Group 1. DJT discussed this meeting with others in the campaign as well including Gates. Kushner showed up late to the meeting and texted manafort during that this was a ‘waste of time’ and texted others to call him to get out and he subsequently left early. The meeting did not provide any information to Trump campaign.
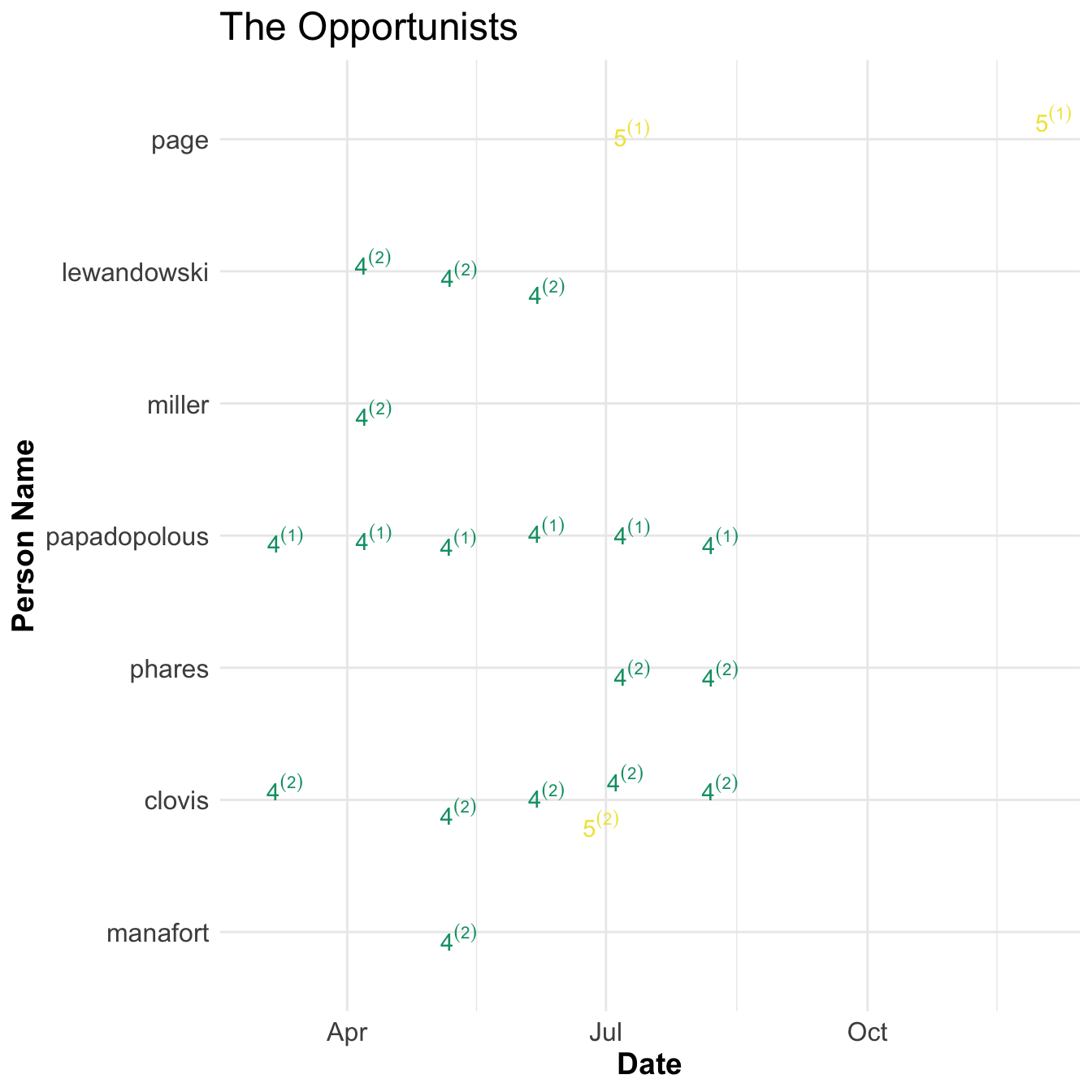
The Oppurtunists
- Group 4
- mifsud, polonskaya, timofeev, millian
- Group 5
- klimentov, poliakova, peskov, dvorkovich
Papadoplous and Page had similar experiences with the Trump campaign and they both seemed to be in it for the opportunity it presented themselves. Both padded his resume to look more important than he was to get the job and both foreign policy advisory roles.
Papadoplous got the job of foreign policy advisor in march 2016. He met Mifsud, a Maltese Professor, in Rome at a meeting for London Centre of International Law Practice shortly after. Upon learning that Papadoplous was employed by campaign Mifsud took interest and spoke of his Russian connections. Papadopolous, thinking that having more russian connections could help his stature in the Trump Campaign, pursued this relationship. They met the following week in London where Mifsud introduced him to Polonskaya. Papadopolous relayed his new contacts with Clovis and received an approving response. This relationship continued and Mifsud said Russia had ‘dirt’ on Clinton during a meeting in late April. Ten days later he told a foreign official about his contacts and knowledge of dirt on Clinton. He then discussed a Trump meeting with Putin to Lewandowski, Miller, and Manafort. Manafort made clear that Trump should not meet with Putin directly.
Page also joined the campaign in march 2016 as a foreign policy advisor. He had previously lived and worked in Russia and had several Russian contacts. He was invited to talk to the New Economic School in Russia in July and asked for permission. Clovis responded that if he went he could not speak for Trump Campaign. His talk was critical of US policy towards Russia and was received welcomingly from Russian Deputy Prime Minister and others. After he met Kislyak in July in Cleveland. These activities drew the attention of the media and was removed from campaign in late september.
After Election Page went to Russia in an unofficial role after the election in late 2016. He again met with Russians in Group 5.
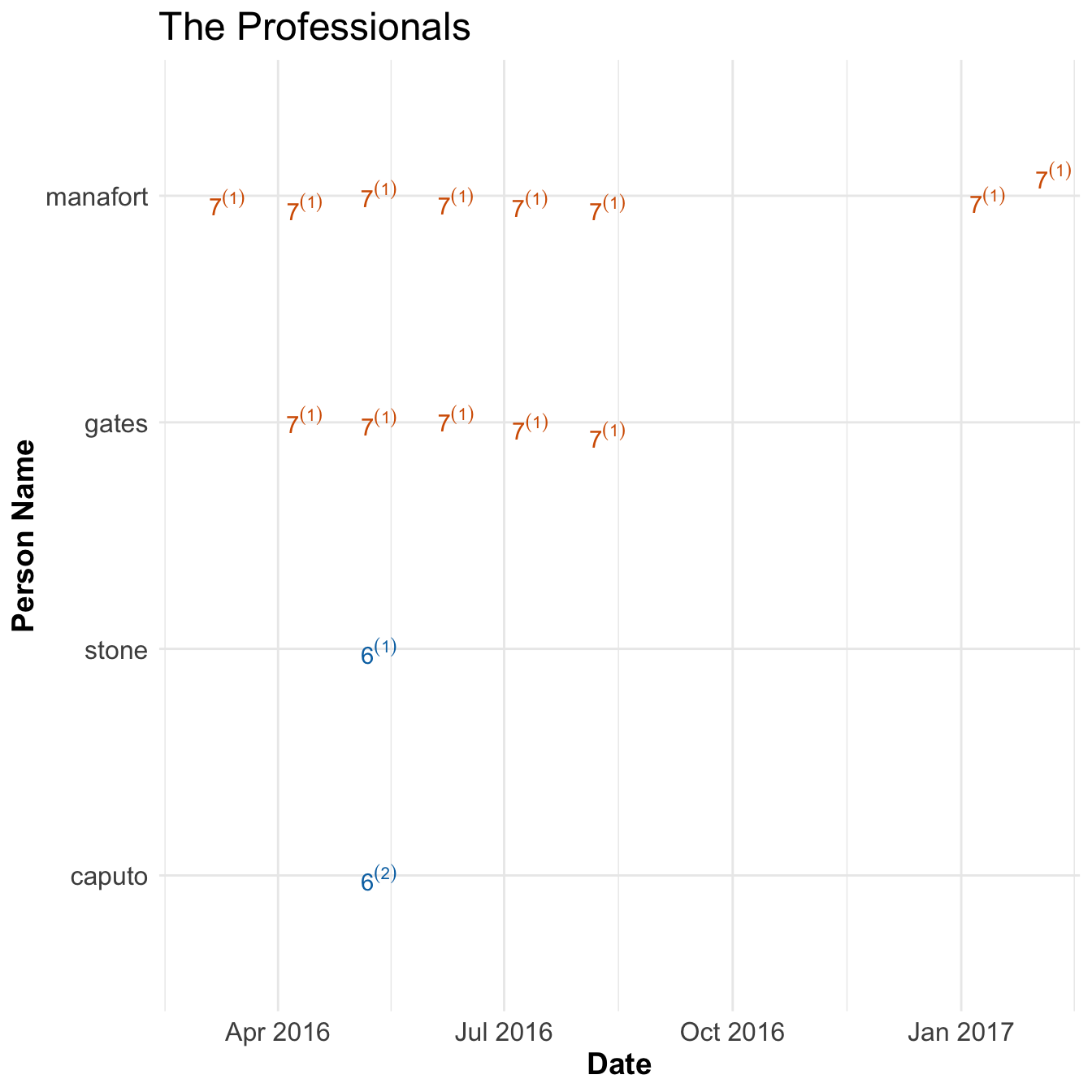
The Professionals
- Group 6
- Group 7
- kilimnik, deripaska, boyarkin, oganov
Paul Manfort and Roger Stone are political consultants and previously worked together. Roger Stone worked alongside the campaign to help but was never officially apart of the campaign. Manafort joined in March 2016 and was the chairman between June and August.
Caputo set up a meeting Stone with Group 6, Oknyansky and Rasin, to get dirt on Clinton in May 2016. Rasin claimed to have information on money laundering activities by Clinton. Stone refused the offer because they asked for too much money.
Also, Stone had some contact with the twitter account Guccifer 2.0 (not shown above). This was the front used by the GRU to release stolen documents. Curiously, his name was redacted on page 45 in the Mueller report because of ‘Harm to ongoing matter’. Seems a little weird to redact something when it’s
public information.
From March 2016 until his depart Manafort gave and ordered Gates to give campaign updates to Kilimnik. Kilimnik is thought to be a Russian spy and has connections with Deripaska, a Russian billionaire who Manafort owed money to. Manafort gave polling data on the Trump campaign and met with Kilimnik twice in person; once in May and then again in August. It’s not clear why Manafort gave this data to Kilimnik although Gates thought it was to ingratiate himself to Deripaska. Deripaska and his deputy Boyarkin were subsequently sanctioned by the US Treasury.
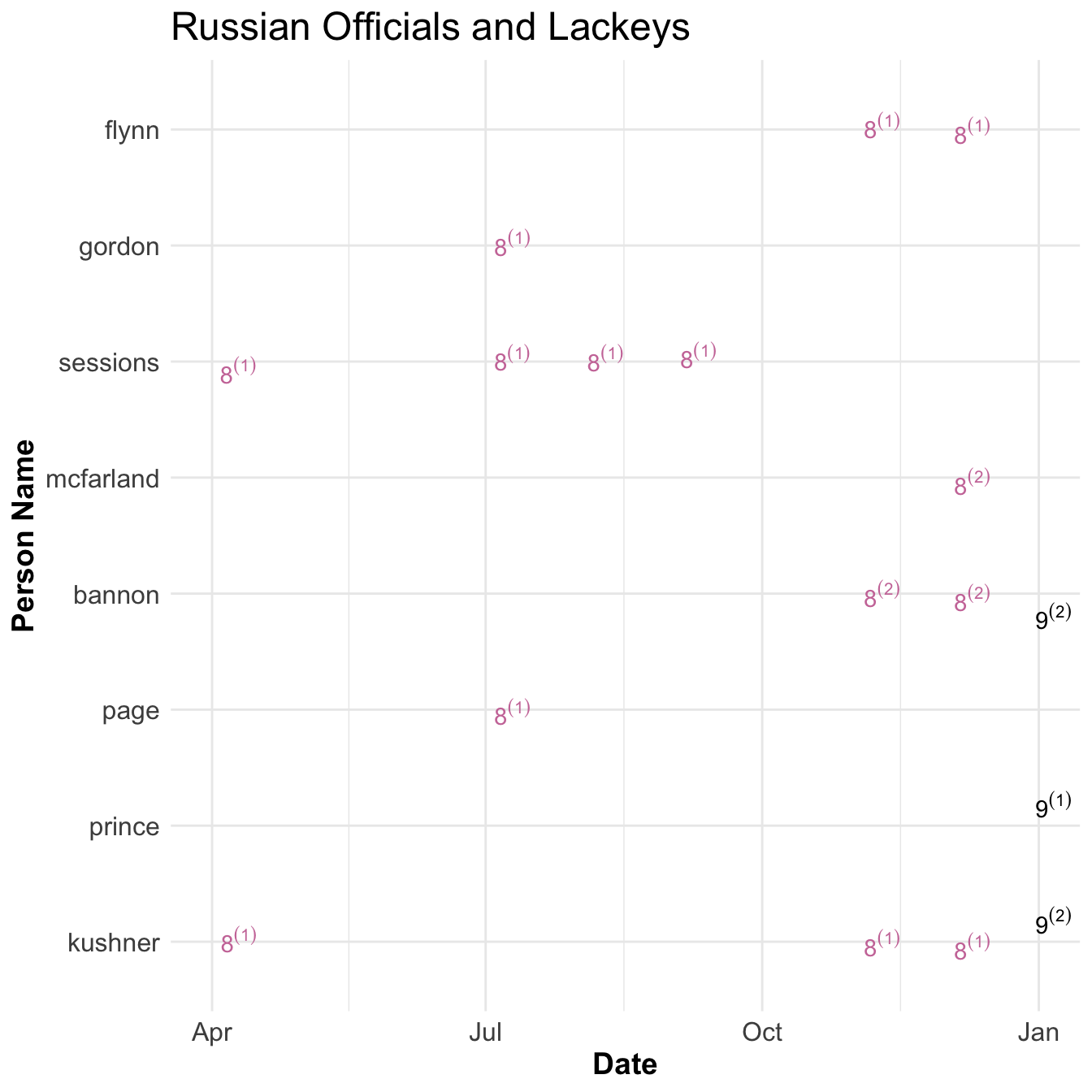
Russian Officials and Lackeys
The final groups deal with Russian Officials and and Putin’s Billionaires.
Sessions and Kushner met with Kislyak, the Russian Ambassador to the US, first in April at a Trump Foreign Policy Conference. These were brief handshake affairs that lasted about a couple of minutes. Sessions does not recall seeing Kislyak.
Sessions, Gordon, and Page met with Kislyak at the Republican National Convention in July. He was one of approximately 80 foreign ambassadors to the US that were invited. Gordon and Sessions met with Kislyak for a few minutes after their speeches. Gordon, Page, and Kislyak later sat at the same table and discussed improving US Russian Relations for a few minutes.
Gordon received an email in August to meet with Kislyak but declined due to ‘constant stream of false media stories’ and offered to rain check the meeting.
In August Russian Embassy set up a meeting with Sessions in Kislyak and the two met in September at Session’s Senate office. Meeting lasted 30 minutes and Kislyak tried to set up another meeting but Session’s didn’t follow up. Sessions got into trouble by not disclosing his meetings with Kislyak and was part of the reason he recused himself from what became known as the Mueller report.
Following the election in November Kislyak reached out to Kushner but Kushner did not think Kislyak had a direct line to Putin and was therefore not important enough to talk to. Nevertheless Kushner met with Kislayk in November at Trump tower and invited Flynn and spoke for about 30 minutes about repairing US Russian Relations. Kislyak suggested using a secure line to talk to Russian generals about Syrian war. Kushner said he had no secure lines to use and asked if they could use russian facilities but Kislyak rejected that idea.
Kislyak tried to get another meeting with Kushner but Kushner sent his assistant instead. Kislyak proposed meeting with Gorkov, the head of a Russian owned bank, instead. Kushner agreed and they met in December. Kushner said that meeting was about restoring US - Russian Relations. Gorkov said it was about Kushner’s personal business. They did not have any follow up meetings.
In december Flynn talked with Kislyak about two separate topics. The first was to convince Russia to Veto anti-Israel resolution on settlements in the UN where it was thought the Obama administration would abstain. Russia did not vote against it. The second was to convince Russia not to retaliate against new sanctions for meddling in US elections. Mcfarland and Bannon were aware of Flynn’s discussions about the sanctions. Russia did not apply retaliatory sanctions.
Finally there were two billionaires men that Putin ‘deputized’ to create contacts with the Trump Campaign after the election; Aven and Dmitriev. Aven said recalled that Putin did not know who to contact to get in touch with President Elect Trump. Aven did not make direct contact to campaign but Dmitriev did through two avenues. One was to try and convince Kushner’s friend to setup a meeting. Kushner circulated this opportunity internally but it went nowhere. The other was meeting with Erick Prince, a supporter of Trump but not officially in campaign, in the Seychelles Islands. Prince discussed his meeting with Bannon but Bannon does not have a recollection of it.
Some notable connections
In general these Russian Groupings were distinct in the people they talked to and had little obvious contact with one another. Some notable exceptions are:
- Peskov talked to Cohen and Page independently
- Dmitriev and Peskov might have talked to eachother (p. 149) but there was some ‘investigative technique’ redactions so I’m not sure
- Kilimnik was aware of Page’s December visit to Russia and discussed with Manafort saying “Carter Page is in Moscow today, sending messages he is authorized to talk to Russia on behalf of DT on a range of issues of mutual interest, including Ukraine” p. 166. Leads me to ask: who would know the whereabouts and discussions of other people? Spies. Thats who.
Conclusions on Volume 1
Overall, I get the impression that the Trump campaign did not have the ‘best people’. Cohen tried to make a deal but couldn’t find the right people to talk to. Papadopolous and DJT tried to get dirt on Clinton but couldn’t find anything. Page seemed to use the campaign as a platform to create more connections with Russians. A few ‘friends’ (Stone and Prince) lent a hand but probably hurt Trump’s credibility by dealing with Russians more than they helped him. Manafort, a seasoned campaigner, wasn’t obviously working for Trump… he worked for free after all. It seemed like a group that were willing to do shady things, for their own personal gain, but without the ability to follow through.
SAD!
Conclusions on Analysis
Running text analysis before reading report was very helpful to understanding it. There are just so many connections going on it’s hard to keep track. Running some basic clustering techniques as described above helped me zone into what to look for while reading the report.

















{kind=link}